



Key Takeaways
- Building AI in healthcare almost always runs into the same barrier: too little usable data, which makes synthetic training data, augmentation, and transfer learning essential tools.
- Synthetic data can extend datasets and protect privacy, but without rigorous validation it risks producing artifacts that mislead models instead of improving them.
- Data augmentation adds variety and balance to small datasets, while transfer learning adapts existing models to medical tasks and shortens development cycles.
- Validation across statistical checks, expert review, performance metrics, and privacy safeguards is what separates experiments that stay in the lab from systems that work in real hospitals.
- The future of medical AI will not be decided by who has the most data, but by who makes the smartest use of the data they have.
Is Your HealthTech Product Built for Success in Digital Health?
.avif)
Every attempt to build medical AI runs into the same obstacle sooner or later: there is never enough data.
Building high-quality machine learning models in healthcare is often hindered by the limited availability of large, well-annotated datasets. Data privacy regulations, the high cost of expert labeling, and the rarity of certain medical conditions all contribute to this scarcity. The result is small, imbalanced, or incomplete datasets. These limitations can lead to overfitting, poor generalization, and unreliable performance in real-world clinical settings.
To work around these constraints, researchers and practitioners increasingly turn to three broad strategies: synthetic data generation, augmentation, and transfer learning. Each tackles the scarcity problem from a different angle.
In this blog post, we’ll break down how to work with limited data in healthcare AI. You’ll see how synthetic data can be generated, how augmentation expands small datasets, and how transfer learning adapts existing models to medical tasks. We’ll also cover validation, ethics, and hands-on advice to help you decide when synthetic training data is the right path. Read on for a practical guide to building AI when real data is scarce.
If you're looking to build AI in healthcare but are struggling with limited data, you can also talk to our team about how to validate synthetic training data for real-world use.
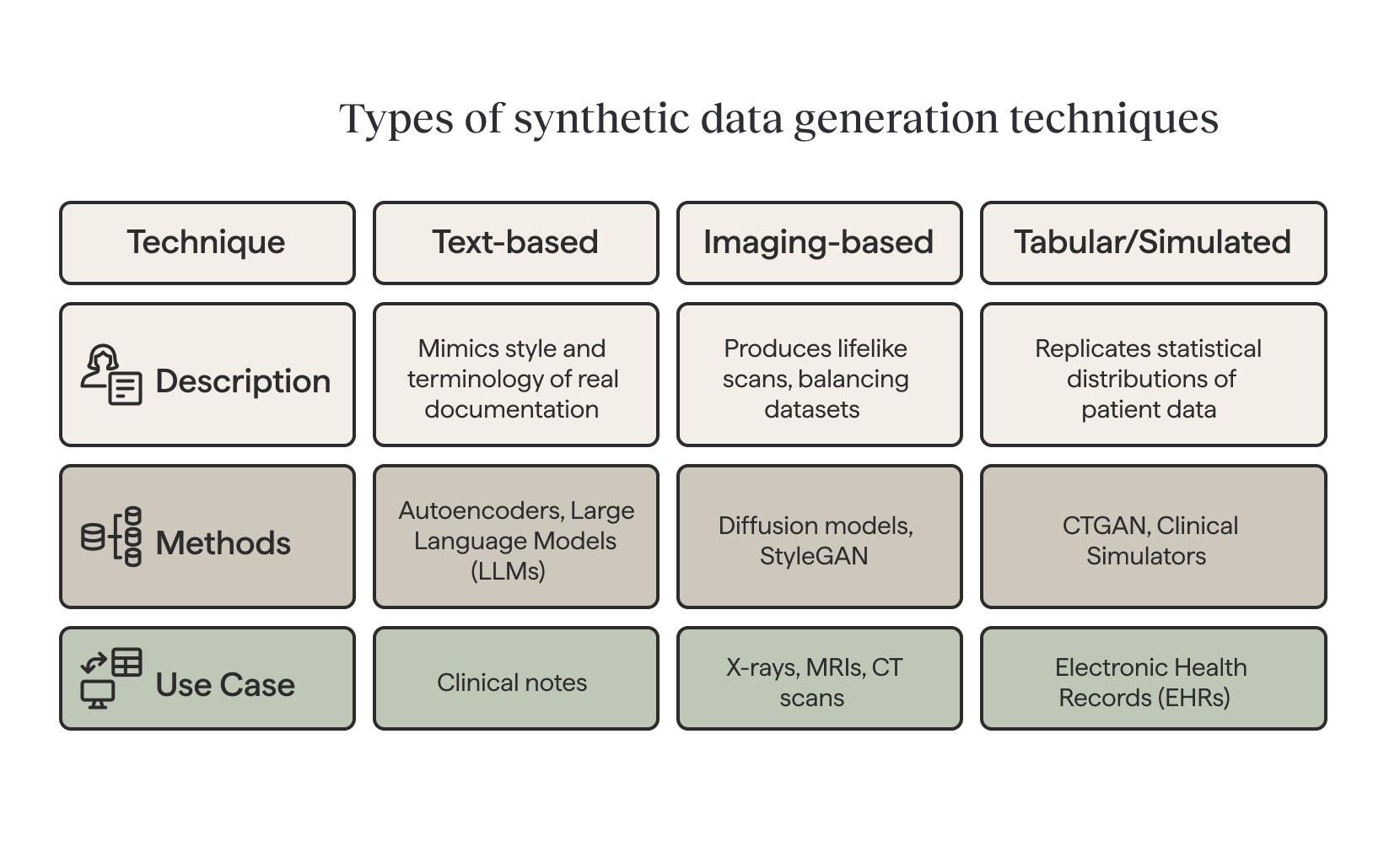
Synthetic data generation techniques
Imagine trying to train a medical AI system to detect rare diseases, but you only have a handful of patient cases. This is where synthetic data becomes a game-changer. By creating realistic, artificial records that reflect genuine medical patterns, researchers can fill gaps and strengthen model performance without relying solely on scarce or sensitive patient data.
In healthcare, synthetic patient data can be generated to train diagnostic models while respecting patient confidentiality.
Text-based generation
Different types of data call for different approaches. For clinical text, autoencoder-based methods and large language models (LLMs) can generate synthetic notes that mimic the style and terminology of real documentation. Variational autoencoders (VAEs) create new data by compressing input data into a lower-dimensional representation.
Imaging-based generation
For medical imaging, advanced generative models such as diffusion models and StyleGAN can produce lifelike X-rays, MRIs, or CT scans—balancing datasets that would otherwise be skewed toward common conditions.
For medical imaging, advanced generative models such as diffusion models and StyleGAN can produce lifelike X-rays, MRIs, or CT scans—balancing datasets that would otherwise be skewed toward common conditions. Synthetic data helps to balance datasets that are imbalanced by generating additional examples of rare events, improving model performance.
Tabular and simulated data
In structured datasets like electronic health records (EHRs), techniques such as CTGAN can replicate statistical distributions of patient data. Conditional sampling allows for targeted cohorts, for example, generating synthetic data for diabetic patients over 60. Beyond purely generative methods, clinical simulators (from physiological heart and lung models to synthetic EHR generators) offer controllable, high-fidelity datasets for training and testing AI systems. It can take various forms, including text, numbers, tables, images, and videos.
A study found that GPT-4o, in zero-shot prompting, produced 6,166 synthetic case records. In Phase 2, 92.3 % of the 13 clinical parameters showed no statistically significant difference versus real data, i.e. fidelity. (source)
Of course, synthetic data is most powerful when used to augment, not replace, real-world data. Careful validation is essential to ensure the generated records improve robustness without introducing artifacts or hidden biases.
Data augmentation strategies
Data augmentation is often the first line of defense against limited training data in healthcare AI. It creates variations that improve generalization without requiring new samples. These techniques can also generate new data to supplement existing datasets, helping to enhance model performance.
Geometric and photometric adjustments
In the case of medical images, geometric transformations must respect anatomical constraints. For instance, rotations stay within ±15–30° for chest X-rays but can extend to ±180° for dermoscopy. Horizontal flipping requires caution when dealing with asymmetric organs like the heart. Photometric adjustments simulate acquisition differences through contrast jittering, brightness shifts, or Gaussian noise. CT and MRI scans, meanwhile, benefit from specialized window and level perturbations.
Advanced techniques such as elastic deformation and StyleGAN2-ADA can generate realistic pathological variations. They are most effective with 5,000+ medical images but can also work through fine-tuning on smaller datasets. Generated samples, however, always require clinical validation before training use.
Textual augmentation methods
By contrast, text augmentation has to preserve medical meaning while adding linguistic variety. Synonym replacement can rely on UMLS APIs for terminology and BioBERT embeddings for context. This ensures that critical entities—such as ICD-10 codes, drug names, or lab values—remain intact.
Back-translation through intermediate languages (EN→DE→EN for conservative, EN→ZH→EN for more aggressive shifts), filtered by high BLEU scores, ensures quality. LLM-based paraphrasing with carefully tuned parameters (temperature 0.3–0.7) also works when prompts explicitly preserve clinical entities, measurements, and timelines.
Time-series and signal augmentation
When it comes to tabular and time-series data, methods must maintain both statistical integrity and physiological validity. SMOTE addresses class imbalance, while controlled noise injection and feature permutation create safe variations.
Signal augmentation for ECG, EEG, and other physiological data may involve time warping, amplitude scaling, or frequency-dependent jittering via FFT. Specialized GANs, such as ECG-GAN, can even generate entire synthetic signals conditioned on patient metadata.
In one GAN-based liver lesion classification task (only 182 CT image ROIs), classical augmentation yielded 78.6 % sensitivity and 88.4 % specificity; adding synthetic data improved to 85.7 % sensitivity and 92.4 % specificity. (source)
These strategies collectively enable robust model training, even when annotated data remains scarce. Still, every augmented dataset requires validation to avoid introducing clinically meaningless patterns.
{{lead-magnet}}
Transfer learning approaches
Even with synthetic data and augmentation, many healthcare AI projects face limitations in sample size. Transfer learning helps bridge this gap by reusing knowledge from models trained on large datasets and adapting it to medical tasks.
A common strategy is to fine-tune a pretrained model on a smaller dataset while freezing the earlier layers. This allows the system to retain broad features while adjusting to domain-specific details.
In imaging, pretrained models provide a foundation for recognizing anatomical structures and disease patterns with fewer labeled examples. In clinical text, models trained on biomedical corpora bring an understanding of medical terminology, improving tasks such as diagnosis classification, information extraction, and risk prediction.
In practice, this means a hospital team can fine-tune a general model on a handful of local patient scans or notes—achieving clinically useful performance much faster than training from scratch.
Beyond supervised transfer, self-supervised learning on large volumes of unlabeled medical data is gaining momentum. These models learn general representations from raw text, images, or signals and then adapt to smaller labeled datasets. The result is improved efficiency and performance, even when annotations are limited.
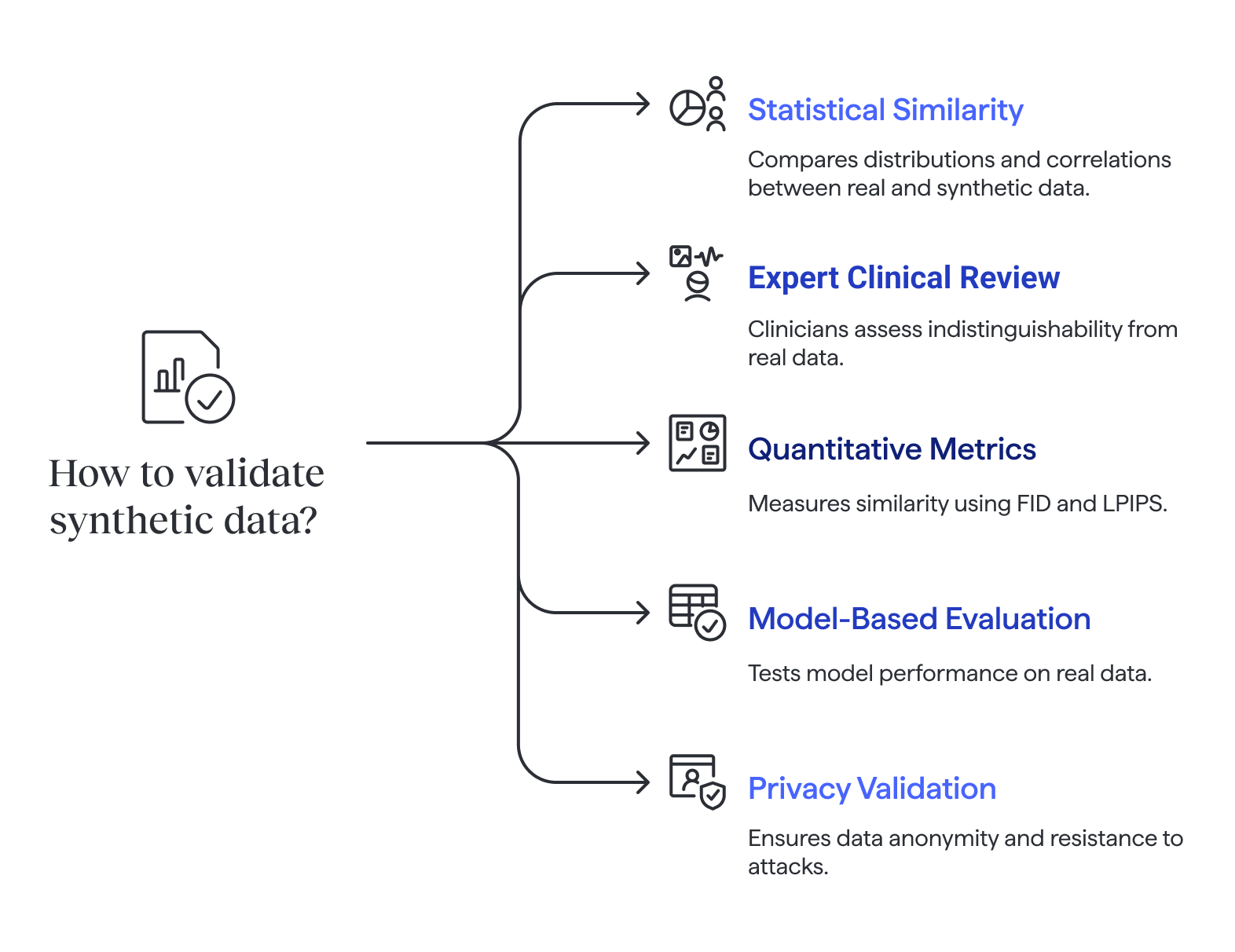
Validation methods
Of course, synthetic data is only valuable if it reflects real-world patterns and maintains patient privacy. That’s why validation must be multi-layered. Validation ensures that synthetic data does not contain the same information as the original data, protecting privacy while preserving the utility needed for analysis.
Statistical similarity checks
Statistical checks compare distributions, correlations, and other key properties between real and synthetic data.
Yet even with these checks, studies show that synthetic datasets often fail to preserve multi-signal correlations—for example, relationships between different physiological signals—which can distort downstream models if overlooked.
%201.png)
Expert clinical review
Expert review adds another layer: clinicians or radiologists can perform blinded assessments, evaluating whether records or images are indistinguishable from real data. In some cases, experts are asked in Turing-test style experiments to tell real from synthetic. Difficulty in making the distinction suggests realism.
Quantitative performance metrics
Quantitative metrics complement human judgment. These metrics are used to assess the quality of data generated by synthetic data methods, ensuring that computationally produced samples closely resemble real-world data. For images, FID (Fréchet Inception Distance) measures similarity between distributions of real and synthetic samples, while LPIPS (Learned Perceptual Image Patch Similarity) reflects human-like perceptual similarity. Together, expert inspection and quantitative scores provide strong evidence of quality.
Model-based evaluation
Model-based evaluation goes further. A model trained on synthetic data is tested against a held-out real dataset to measure metrics such as accuracy, F1 score, or ROC-AUC. Synthetic data is often used to train models when real data is limited, sensitive, or subject to privacy regulations. This confirms whether synthetic data captures clinically relevant patterns. Additional checks may simulate robustness by testing on noisy labels, varied patient populations, or external hospital data.
Privacy and re-identification risks
Finally, privacy validation is critical. Tests include k-anonymity to ensure no single record can be re-identified, as well as resistance to membership inference attacks. Pseudonymized data replaces sensitive data with artificial identifiers, but may still contain real world information that requires protection under privacy laws. Researchers may also check whether sensitive attributes could be inferred from synthetic datasets. These steps ensure safe use without exposing patient information.
Ethical and regulatory considerations
Using synthetic data in healthcare AI requires meeting strict ethical and regulatory standards. HIPAA and GDPR compliance are essential, and each synthetic record should be tested to confirm it cannot be re-identified. Fully synthetic data contains no real patient information, while partially synthetic data combines real and artificial elements to balance privacy and utility. Membership inference resistance, as well as traceable documentation of the generation pipeline, supports both safety and regulatory readiness.
Synthetic data can augment training and testing but is rarely sufficient for regulatory approval. FDA- and CE-marked medical devices still demand validation against real clinical datasets. Synthetic data can also be used to supplement publicly available data, and organizations operating in the European Union must comply with strict data protection regulations. Privacy-preserving methods, such as DP-GANs or gradient clipping, can be integrated to further reduce risk.
Taken together, rigorous validation, transparency, and privacy-focused techniques make it possible to use synthetic data responsibly to improve model robustness while respecting ethical and legal boundaries.
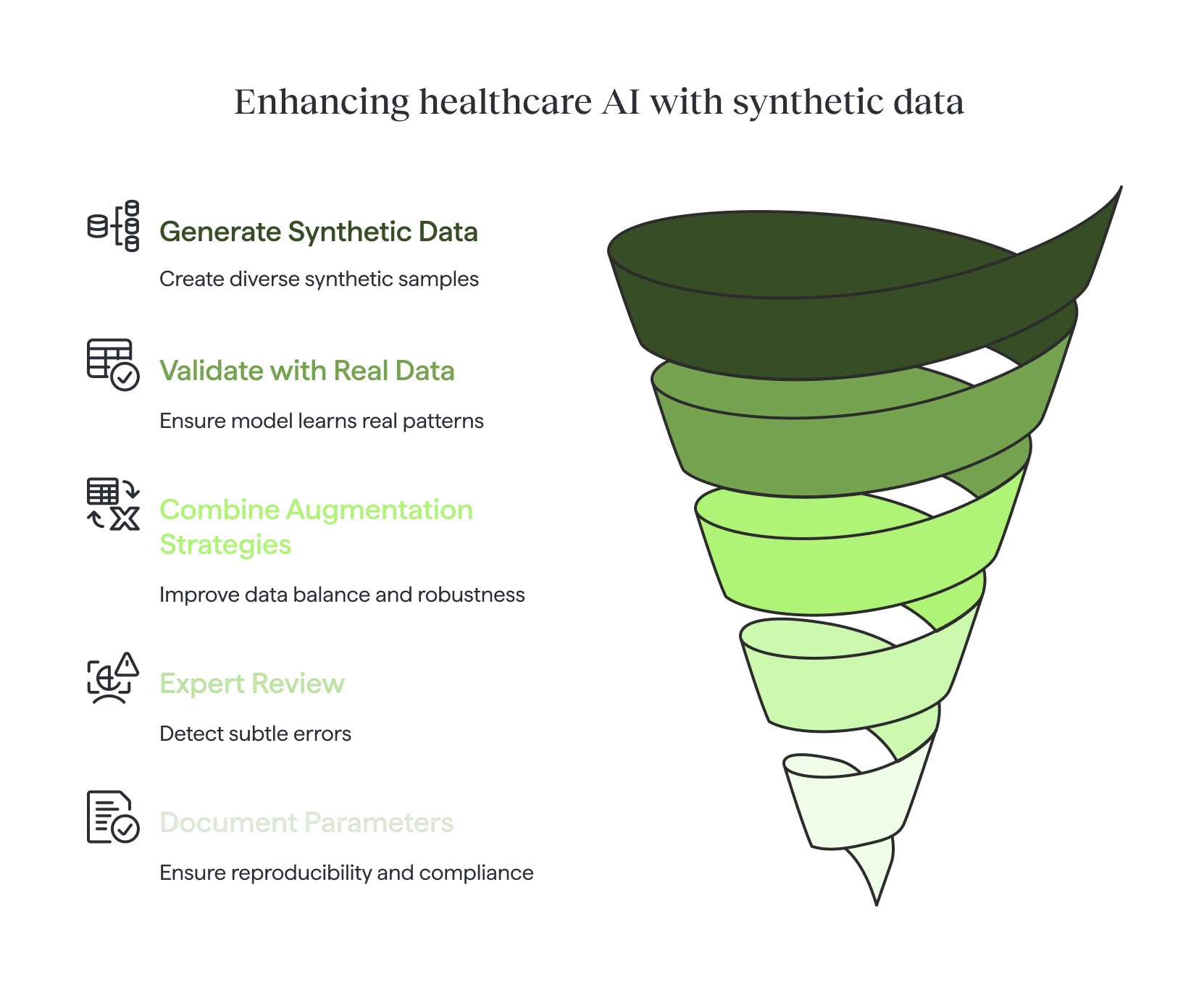
Practical advice checklist
When working with limited datasets, synthetic data and augmentation can be powerful tools—but only when applied responsibly.
- Validate on a real, held-out dataset. Synthetic data can expand diversity, but only real patient records confirm whether the model has learned meaningful patterns.
- Avoid training exclusively on synthetic data. Synthetic samples should complement, not replace, real-world examples.
- Combine multiple augmentation strategies. Especially for rare classes, blending geometric, photometric, and generative methods improves balance and robustness.
- Include expert review where possible. Clinicians can detect subtle errors that automated checks may miss.
- Document all generation parameters. Clear records of algorithms, seeds, and settings ensure reproducibility and regulatory readiness.
Conclusion
Working with limited datasets is the rule rather than the exception in healthcare AI. Synthetic generation, careful augmentation, and transfer learning can bridge critical gaps, but only when paired with rigorous validation and ethical safeguards.
Used responsibly, these methods don’t just help researchers overcome scarcity. More importantly, they allow medical AI systems to move closer to real clinical impact, even in the absence of big data. Data may be scarce, but ingenuity isn’t—and that is what will shape the future of medical AI.
In the end, the future of medical AI will belong not to those with the most data, but to those who know how to make the most of the data they have.
Turning a training data strategy like this into a deployed clinical model end to end is what Momentum's AI implementation service does.
Frequently Asked Questions





%20(2).avif)



