.avif)

Key Takeaways
- Apple Health's XML export contains every workout, sleep session, and heart rate reading your devices ever recorded, but it's several hundred megabytes of nested tags no off-the-shelf dashboard was built to consume.
- FastMCP turns your Apple Health export into an MCP server Claude queries directly. No custom API layer between the LLM and your data, just structured access through the Model Context Protocol.
- The useful output isn't the summary numbers, it's catching patterns you'd miss scanning raw data: VO2 max declining across a training block, recovery scores dropping before an injury appears.
- n8n handles scheduling and delivery without custom infrastructure. Weekly coaching emails run automatically once the workflow is configured, no cron jobs or backend maintenance required.
- This is the prototype. Open Wearables extends the same architecture to Garmin, Oura, and Fitbit under a unified API. MIT-licensed, 551 GitHub stars, 16 contributors, free to fork and build on.
Is Your HealthTech Product Built for Success in Digital Health?
.avif)
February 2026 Update: The Apple Health MCP Server has evolved into Open Wearables, a self-hosted platform that unifies wearable health data from Apple Health, Garmin, Polar, Suunto, and Whoop. As of v0.3.0-beta, Open Wearables has 551 GitHub stars, 48 forks, and 16 contributors. The Apple Health MCP Server remains available as a standalone tool at github.com/the-momentum/apple-health-mcp-server and is the reference implementation for Apple Health data in the broader platform.
Apple Health is a great source of various metrics. But what do all of these metrics mean? With each new version of iOS and WatchOS, we get more and more insights, but it's still far from ideal. I'll give you an example from my personal life.
Who Should Build This?
This pipeline is practical for a few different audiences.
Developers building fitness or wellness applications who need to evaluate Apple Health as a data source before committing to native HealthKit development. You can validate the data model, the AI layer, and the user-facing workflow in a weekend before investing months in a native iOS app.
Teams building health features for clients who want a working prototype to demonstrate rather than a slide deck.
Coaches and trainers who want structured, queryable access to athlete health data from Apple devices without building custom infrastructure from scratch.
Personal builders who want to run their own health analytics without exporting to a third-party service.
The stack runs locally or on Railway with a free tier. For production apps requiring real-time sync, Apple HealthKit's native SDK is the right path but for prototyping and validating the AI layer, this approach gets you further faster.
The Problem: Apple Health Data Is Locked in an XML File
Apple Health stores every workout, sleep session, heart rate reading, and step count your devices have ever recorded. Getting anything meaningful out of it means parsing a several-hundred-megabyte XML export or building native HealthKit integrations that require App Store entitlements and months of development. Most of that data sits unused.
This is the story of how our engineering team at Momentum spent a hackathon building a pipeline to change that: an MCP server that makes Apple Health data queryable by Claude, a Python backend that ingests the XML export, and an n8n workflow that delivers automated weekly coaching summaries. The full stack took one weekend to build. Here is the architecture, the code, and what we would do differently.
A while back, I was reading Outlive. One chapter made the biggest impression on me. It was about VO2 max, what this metric says about our health, and what its value means for our current and future capabilities. I really love hiking, so Peter Attia couldn't have reached me with a better message. He showed what different values of VO2 max mean when it comes to fitness capabilities at different ages. The graph shows the decline of maximum oxygen uptake (VO2 max) with age for three fitness groups. You can clearly see that someone in high fitness condition (95th percentile) at age 62 has the same aerobic capacity as an average 25-year-old. Meanwhile, someone in poor condition (5th percentile) may struggle with simple activities like quickly climbing stairs already at age 45.
.png)
So I was really curious: what's my current VO2 max? I was pretty confident about this value since I considered myself a pretty fit person. I ran quite a bit, played soccer, cycled, played squash, and walked a lot. So it couldn't be bad. But when I checked the values, it turned out my VO2 max didn't look that good at all.
I was below average. I looked at the table from the book again and realized I had to do something about it. I checked how I could increase this value. One way was interval running. I thought, why not? After all, I like running; I only needed to change the type of training.

So I added intervals to my running, and after a while, I started seeing results. I was curious, though: is my running technique and interval training good? Besides progress in VO2 max values, am I also making progress in my times? Could any of my habits (like getting relatively little sleep) be negatively affecting these values? I couldn't find answers to any of these questions directly in the app, so I started wondering what if I used LLMs to analyze my data?
That's how the idea for creating an Apple Health MCP server was born, which you can read more about here.
After a while, it turned out this solution had two main problems:
- Difficulty with installation and setup, though it wasn't a problem for me personally since you only need to do it once, many friends asked me for help, and every time it took forever.
- Data updates, the server relied on an export.xml file, which was the result of manually exporting data from Apple Health. In the long run, this was a really annoying process because to have current data, I had to spend about 10 minutes each time on manual export and then transfer the data to my computer.
But finally, an opportunity came up to solve these problems. That opportunity was a hackathon.
Architecture: How We Built the Apple Health Analytics Pipeline
The goal was simple: solve the two problems above. My personal ambition was to “free” my data from Apple Health, make it available through an API, and then expose it to LLMs (like Claude) via an MCP server. The stretch goal was to add automation that would, for example, send a weekly summary comparing the results to the previous week.
So our architecture looked roughly like this:
.png)
Below you'll find a short description of each system component.
Step 1: Getting Apple Health Data Out of Your iPhone
The only way to have continuous access to Apple Health data is through integration with Apple HealthKit, so we needed an application. Our hackathon team didn't have a mobile developer, and there were only three of us. We determined this might be too ambitious a task for several hours. We therefore decided to use the Apple Health Export application, which enabled exporting data to external sources, including an HTTP endpoint.
.png)
Step 2: Ingesting and Structuring Data (FastAPI + SQLAlchemy)
The first component we needed to create was the backend. From building the Apple Health MCP, we already had experience with what data is available in Apple Health and what data models we would need. However, we made the decision that at the hackathon we would only handle workout data, omitting health metrics. The demo was supposed to focus on summarizing workout data, providing interesting insights, and motivation to keep pushing.
We based the backend on FastAPI. For this purpose, we used python-ai-kit, a boilerplate that significantly accelerates the initial steps of application development. Thanks to this, we could focus on the actual work:
- creating models
- exposing a webhook consuming data sent by the mobile application
- exposing an endpoint returning workout data
That was really quick. With the help of generative AI (Cursor), we built all of these parts pretty fast; however, it wouldn't have been possible without knowing how Apple Health data is structured, so we could use the experience from building the Apple Health MCP Server.
The most important model was Workout:
This model captures comprehensive workout information, including:
- Temporal data: workout duration and start/end times for time-series analysis.
- Performance metrics: active energy burned, distance covered, workout intensity.
- Environmental conditions: temperature and humidity during exercise.
- Detailed heart rate insights through relationships (real-time HR data during workouts, post-workout recovery rates, and energy expenditure patterns).
- Location context: indoor vs. outdoor activities.
Looking at this carefully, you'll realize it needs improvements, for example:
- Lack of indexing on commonly queried fields (start/end dates, location, workout name)
- No validation for data ranges (e.g., temperature, humidity, duration must be positive)
- Workout type field is a string instead of an enum
- No source tracking to identify data origin (Apple Watch, iPhone, third-party apps)
However, due to hackathon time constraints, we prioritized getting a working prototype over data model polishing.
Step 3: Making the Data Queryable via FastMCP
The next step was to create an MCP server. We again leveraged python-ai-kit, built on top of the FastMCP framework. Below you can see how this boilerplate streamlines project creation.
Since FastAPI, which we were using in our backend, exposes OpenAPI by default, we were able to ask Cursor to add two tools: get_heart_rate and get_workouts.
The logic was simple. The tools were essentially API wrappers without adding too much custom logic on top of them. However, it was a hackathon, and we simply needed a working version.
By basing the server on FastMCP, we were able to leverage deployment via fastmcp.cloud. The only thing we had to do was connect and specify the GitHub repository where the MCP server was located, and that went very quickly.
fastmcp.cloud also provides tools for debugging MCP servers and the ability to view logs, which is very useful during development.
-kopia%202.png)
Step 4: Automating Weekly Summaries With n8n
Since we still had some time left, we decided to add automation in N8N.
.png)
It was pretty straightforward, which is why I love N8N. It's ideal for very fast prototyping due to many ready-made integrations.
What you can see on the diagram (from the left):
- HTTP request node: it requested our backend to fetch workout data. We used query params to filter workouts only from the latest month.
- AI summary node: it took the data returned by the API, then, using an OpenAI model, prepared a summary. We had quite a bit of fun creating prompts and setting the tone of voice. Some of the generated summaries weren't nice.
- Summary sending by e-mail node: it's quite self-explanatory.
N8N allows you to save the flow configuration in a .json file, so it’s easy to experiment and keep a stable version safe in the repository.
Step 5: Claude as the Insights and Coaching Layer
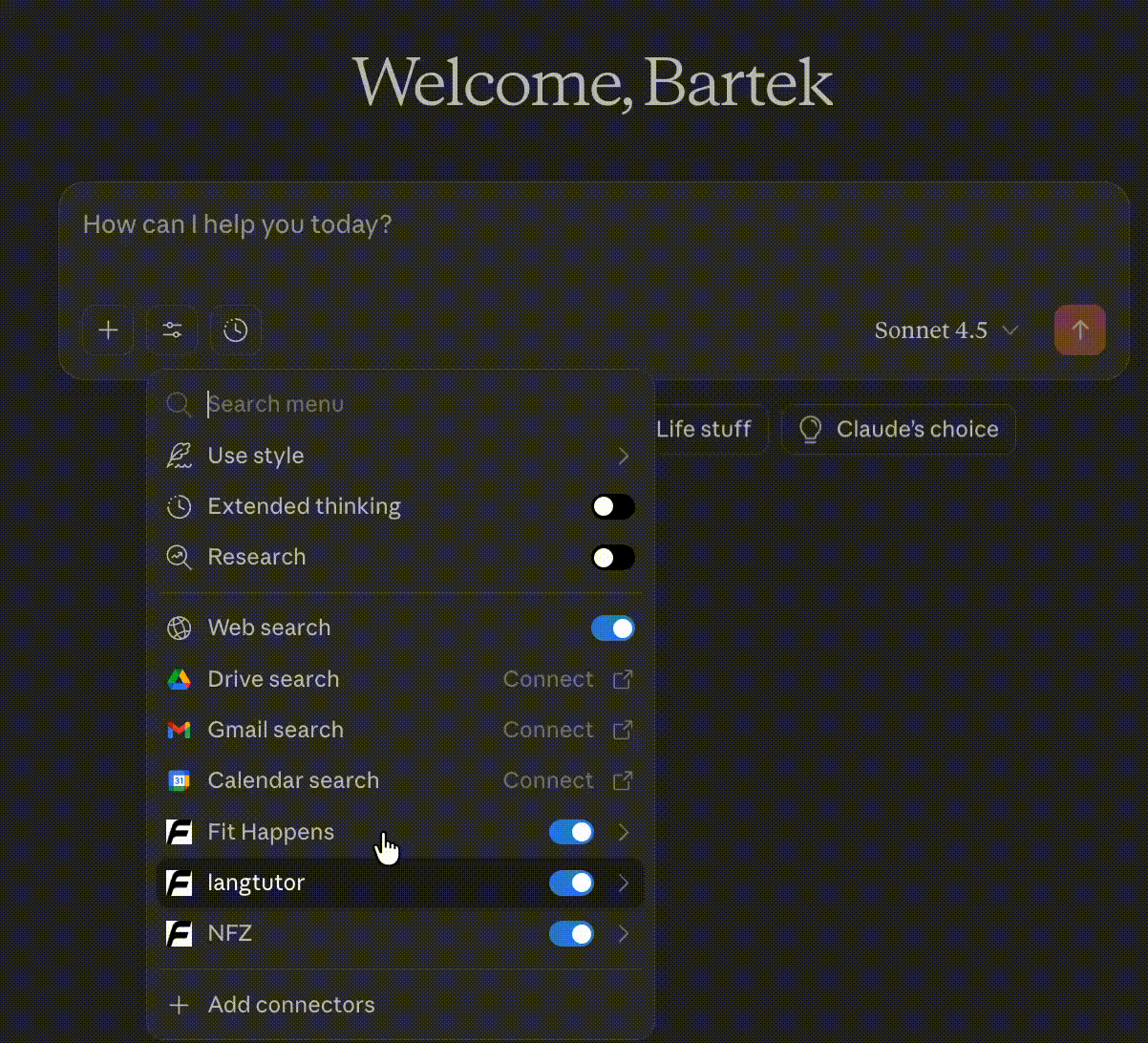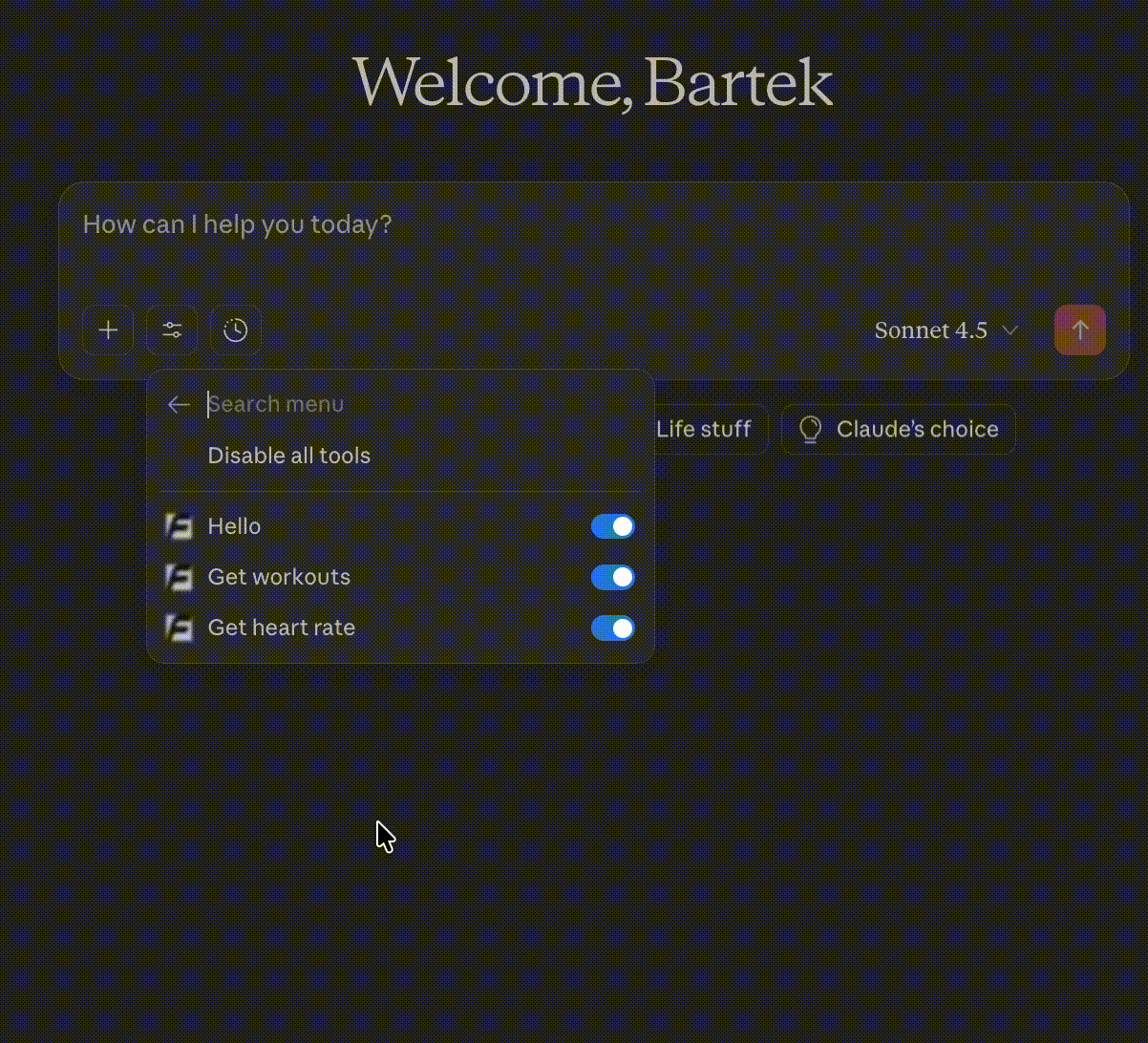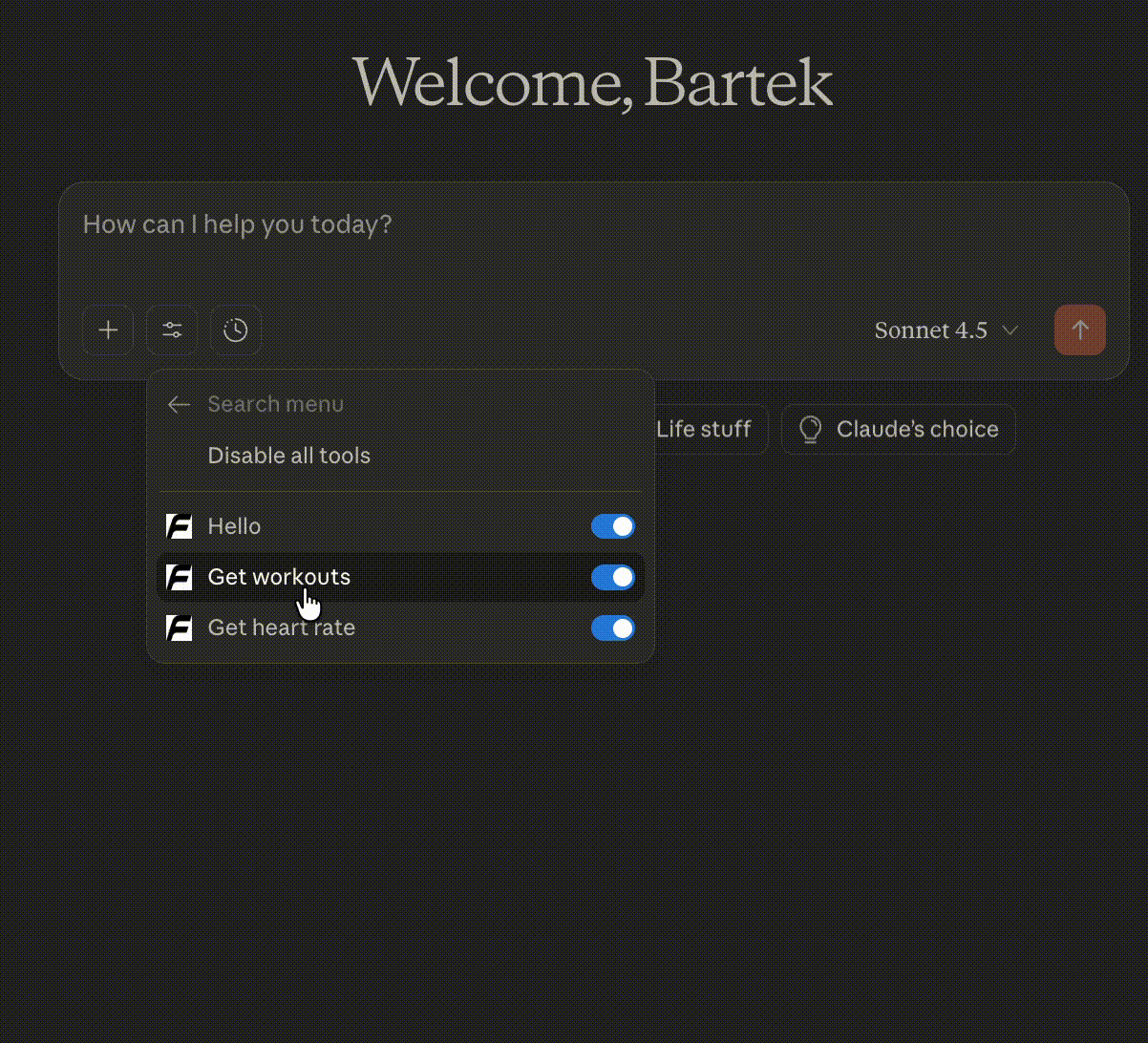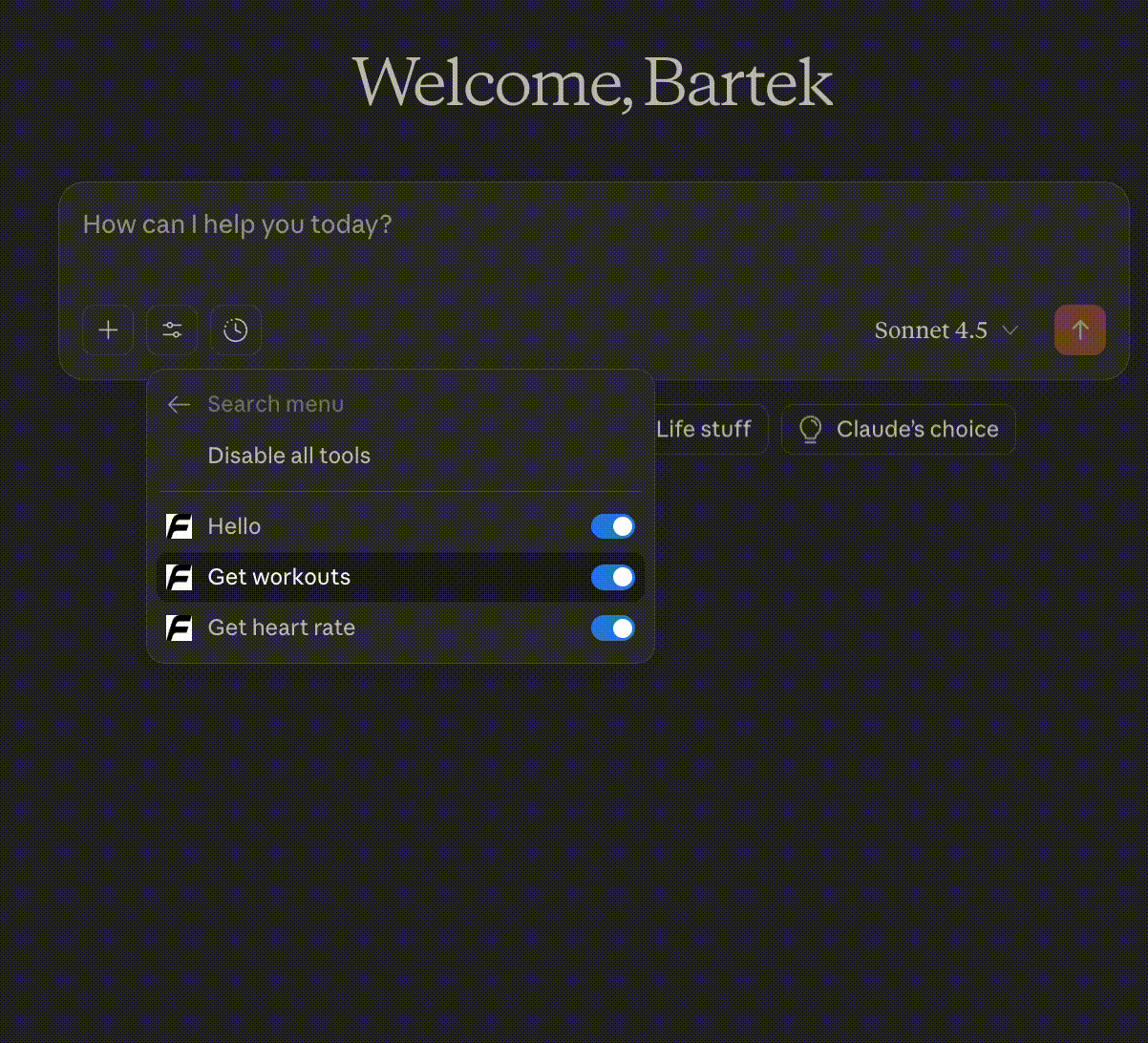
To test our MCP server, we used Claude. Since the server was available online, the configuration was very straightforward.
Claude → Settings → Connectors → Add custom connector → Set name and URL → Done.
Tip: If you're using an enterprise Claude subscription, the “Add custom connector” option may be unavailable to you. Custom extensions must be activated by the organization administrator. Then it will be possible to select it from the “Browse connectors” list.
Once added, we could check if Claude could see all the needed tools.
Results: What AI-Generated Fitness Coaching Actually Looks Like
Demo time came faster than we expected. Like every team, we had three minutes to present our solution.
I started the presentation by asking Claude what it thought about my September activity. The summary was quite comprehensive and aligned with reality (I had to check in the Apple Health app because I didn't think I had worked out that many times in total).
-kopia%204.png)
I also asked it about the highlights.
-kopia%205.png)
Unfortunately, we didn't have time to construct questions to sensibly utilize the data from the MCP tool that returned heart rate data. If you look closely, not everything worked perfectly, the calorie count was incorrectly returned for some reason. It's impossible that I burned 1,740 calories during a ~7 km run. But it was a demo, and nobody noticed.
If you read the introduction of this article, you may also notice that although I also cared about analyzing my VO2 max, the summary doesn't mention it at all. That's right. As I mentioned during the backend implementation, we decided to severely limit the scope of supported data due to limited time.
Next, we presented the result of our automation created in N8N. For the demo, we decided to choose a gentler version of the coach (though still demanding).
-kopia%206.png)
As you can see, I have some things to improve.
We managed to ensure continuous data flow (which was previously a problem) and demonstrate that, thanks to the MCP server, our chosen LLM client has continuous access to the data. We were also very satisfied with how python-ai-kit, which we've been intensively developing recently, helped us set up both the backend and the MCP server.
The hackathon repository is available here: https://github.com/the-momentum/fit-happens-hackathon
You'll find all the above-described modules in it: backend, MCP server, and N8N workflow.
How to Run This Yourself
The Apple Health MCP Server is open source under MIT license. The setup uses Docker or uv for dependency management.
Prerequisites:
- Docker (recommended) or uv
- An Apple Health XML export: iPhone → Health app → your profile photo → Export All Health Data
Setup:
Edit config/.env with your configuration. Place the exported Apple Health XML in the project root, then initialize the database. DuckDB is the lightest option to start with:
Connect to Claude Desktop using Docker:
Build the image first:
Then add this to your claude_desktop_config.json (replace <project-path> and <xml-file-name> with your actual values):
Connect using uv instead of Docker:
Find the uv binary path (which uv on macOS/Linux), then add to claude_desktop_config.json:
Restart Claude Desktop after updating the config. Once connected, you can query your data:
- "What was my average resting heart rate last month?"
- "Summarize my workouts from the past 8 weeks."
- "Did my VO2 max change during my last training block?"
For Elasticsearch or ClickHouse at scale, see the full configuration docs. For the n8n weekly summary workflow, the full setup is in the getting started guide.
To share what you build or ask questions, join the Open Wearables Discord.
What We'd Build Differently And What's Available Now
The demo made quite a good impression (though we didn't win). However, for us, it was just the beginning. AI insights based on wearables data are something we've been thinking about for quite some time.
At Momentum, we also collaborated with many companies that utilized wearables data in one way or another, thanks to which we learned a lot about them. We know that time-series data analysis isn't always simple and straightforward.
We plan to develop the solution whose development we started at the hackathon. On our roadmap at this moment is:
- support for all data supported by Apple Health
- fixing all the known issues in the Apple Health MCP Server (issues)
- creating our own open-source application that will allow users to export data but also analyze it directly on their phone
- support for other wearables, such as Garmin, Fitbit, or Oura Ring
- a web application that will allow browsing data and conversing with it
- ability to share data with your trainer and generate custom reports for them
- support for local LLM models (we know how important privacy is in healthcare)
- model fine-tuning
- many more
What’s more, we will build this ecosystem as an open-source solution, so we encourage you to follow our Momentum GitHub to stay informed.
The wearables market is huge. According to the latest data, there are over 450 million smartwatch users worldwide (as of the end of September 2025), and their number is growing rapidly. We believe that these users deserve the opportunity to leverage the latest technologies such as gen AI to receive personalized health and fitness insights.
We’d love for you to explore the Apple Health MCP repo same as Open Wearables repo try it out with your own Apple Health exports, and share feedback or contributions. Open source works best when it’s collaborative, and this is our invitation to build the future of healthtech with us by proposing new features, participating in collaboration, and helping shape the direction of the project.
From Wearable Data to Health Intelligence
If your team has the data flowing and is now figuring out what to do with it, that is the starting point for Signal. Momentum's delivery framework for wearable health intelligence: Blueprint maps your use case, Foundation connects the data sources and deploys the intelligence layer, Intelligence lands coaching, insights, or dashboards inside your app. We bring the integrations, the data layer, and the intelligence. Your team ships the experience.
Frequently Asked Questions
The Apple Health MCP Server is an open-source tool that connects your Apple Health data to Large Language Models (LLMs) like Claude through the Model Context Protocol (MCP). It works by extracting health and fitness data from Apple HealthKit, making it accessible via an API, and exposing it to AI models for analysis.
This enables you to ask natural language questions about your fitness data and receive personalized insights, trend analysis, and actionable recommendations based on your workout history, heart rate data, VO2 max, and other health metrics.
To analyze your Apple Health data with AI, you can use the Apple Health MCP Server to create a connection between your health data and AI models. The process involves:
- Exporting your Apple Health data (either manually or automatically using apps like Apple Health Export)
- Sending it to a backend API
- Querying it through an LLM like Claude
You can ask questions about your workout patterns, track progress over time, identify trends in your heart rate recovery, analyze your VO2 max improvements, and receive personalized coaching advice based on your actual fitness data.
VO2 max is the maximum amount of oxygen your body can utilize during intense exercise, measured in milliliters per kilogram of body weight per minute. It's one of the most important indicators of cardiovascular fitness and aerobic endurance.
A high VO2 max means you can sustain higher intensity exercise for longer periods. Research shows that someone in high fitness condition (95th percentile) at age 62 has the same aerobic capacity as an average 25-year-old, while someone in poor condition may struggle with simple activities like climbing stairs by age 45.
Apple Watch tracks VO2 max and displays it as Cardio Fitness in the Health app, making it accessible for continuous monitoring.
You can export Apple Health data automatically using third-party apps that integrate with Apple HealthKit. One option is the Apple Health Export app, which allows you to configure automated exports to external sources including HTTP endpoints.
You can set up the app to periodically send your workout data, heart rate information, and other health metrics to a REST API. This eliminates the need for manual exports and ensures your data stays current for AI analysis. The app supports various export formats including JSON and CSV, and you can configure which specific data types to export and how frequently.
Apple Health tracks comprehensive fitness data including:
- Workouts: Running, cycling, strength training, hiking, and more
- Heart rate data: Resting, active, and recovery metrics
- Active energy burned and distance covered
- Workout intensity and duration
- VO2 max and cardio fitness levels
- Environmental conditions: Temperature and humidity during workouts
- Location context: Indoor vs. outdoor activities
- Step counts and movement patterns
The Apple Health MCP Server can analyze all of this data to provide insights about your training patterns, recovery metrics, performance trends, and progress toward fitness goals. Future versions plan to support additional wearables like Garmin, Fitbit, and Oura Ring.
Yes, the Apple Health MCP Server is completely free and open source. The code is available on GitHub at github.com/the-momentum/apple-health-mcp-server under an open-source license.
Anyone can explore, use, modify, or contribute to the project. The developers at Momentum are building an entire ecosystem of open-source tools for health data analysis, including the backend API, MCP server implementation, and automation workflows. They encourage community contributions, feedback, and feature proposals to help shape the future of personalized health insights.
You can create automated weekly fitness summaries using workflow automation tools like n8n. The setup involves:
- Creating a workflow that fetches your workout data from the Apple Health API at regular intervals
- Processing the data using an AI model to generate insights and summaries
- Delivering the results via email or other notification channels
You can customize the tone and content of these summaries, from motivational coaching to detailed performance analysis. The workflow can compare your current week's performance to previous weeks, highlight achievements, identify areas for improvement, and provide data-driven recommendations.
To set up the Apple Health MCP Server with Claude:
- Deploy the MCP server (available via fastmcp.cloud or self-hosted)
- In Claude, navigate to Settings → Connectors
- Choose "Add custom connector"
- Enter your MCP server name and URL
Once added, Claude will have access to tools that can query your Apple Health data. You can then ask Claude questions about your fitness activities, and it will automatically use the MCP tools to retrieve and analyze your data.
Note: Enterprise Claude subscriptions may require an administrator to activate custom connectors before they become available.
Currently, the MCP server is designed specifically for Apple Health data, which primarily comes from Apple Watch. However, future development plans include support for other popular wearables such as:
- Garmin devices
- Fitbit trackers
- Oura Ring
Many third-party fitness devices can sync their data to Apple Health, which means you may already be able to analyze data from non-Apple wearables if they integrate with Apple's Health app. The open-source nature of the project means the community can also contribute integrations for additional devices and platforms.


.png)
.avif)